We love to work with big data and to extract and validate informations. We provide reliable data for decision making and a powerful reporting engine with strong visualisation
-
-
Simple Integration of our engine in every existing platform
-
We use - Apache Spark - Kafka - Apache Hadoop and R
-
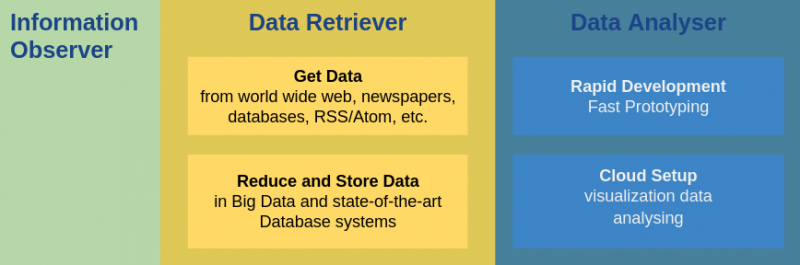
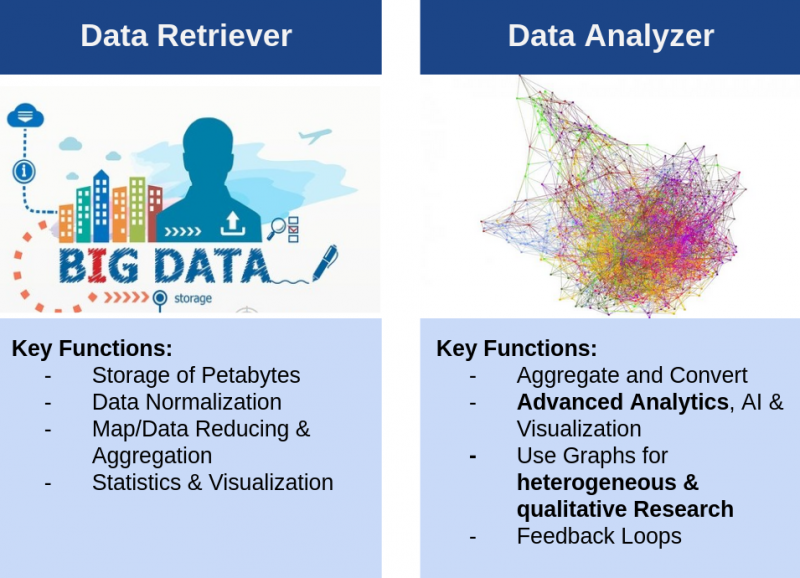
We created the Information Observer, a real time analysis engine for big dataInformation Observer: Semi-automated data-driven system, Information from a wide variety of sources, e.g. open web sources such as online news. Information from accessible databases such as patent offices, Obtain information, store it in a structured way, combine it analytically Output: Provide statements about the market and technologies (and other use cases) Data Retriever fetches, reduces and store data, whereas Data Analyzer focuses on aggregation, visualization and data analytics.
-
# big data
# Apache Spark
# Solar
# Python
# GnuR
# Map Reducer
# Visualisation